
If you can understand the different inputs and outputs of a microbrewery, then you can understand how a web server works.
When you are just getting started with web development, you might wonder… “How exactly do all these new concepts connect to each other when someone types https://mysite.com into their browser?”
Sure, you might know the difference between front-end and back-end, but that only gives you a high-level view.
So, I wanted to create a full guide that explains the connection between client-side (the browser) and server-side (multiple servers).
For example, do you know the difference between a server and a database?
Here’s the deal: the client-server model operates kind of like a microbrewery. And if you can understand the different parts of a microbrewery, then you can understand the basics of web servers.

The Client-Server Model
In this microbrewery, your goal is to sell a high volume of beer to bars, liquor stores and supermarkets. You have a variety of customers that will make large orders every week or every month.
This means that customers will call your sales team or send an email every so often with a request. On the internet, this is known as a client. A client does not share any of its computing power with the other members of the network that it is requesting. It just asks for a certain piece of content or functionality.
On the other side of the equation, your brewery operations team exists so that it can brew beer that will meet the demands of the customers. In this situation, they are the server. That means that they await requests from clients, and use their computing power to share the appropriate resources based on the request.
A common example of a client is a web browser like Chrome. Servers are located in remote location, and are managed by companies like Amazon (Amazon Web Services).

You might think this is one-dimensional, like “Duh, these are the basics of any buying process!” But as you will see in a moment, it can get a little more complicated as more parties enter the picture.
Request-Response Model
As you can see, each side has different roles in the client-server model. The client is the requester, and the server is the respondent.
In a very basic example, a supermarket might send a request like “We need 20 cases of beer.” At some point in the future, your microbrewery will send the response: the beer that was requested.

Similarly, browsers like Chrome send requests to centralized servers, which return the data requested. For example, when you load a page like reddit.com, a server must send a new version of the home page based on the latest upvote and comment data.

So your next question might be, “How does the Internet handle these requests and responses at scale?”
First of all, every device connected to a network (like the Internet) is called a host. Every host has a unique IP address for identification. A DNS server (new type of server) connects a URL like reddit.com to the IP address of a specific server.
When you type in a URL like reddit.com, you are not connecting directly to reddit’s web servers. Instead, you first connect to this DNS server, provided by the hosting company. That server then responds to your request with the specific address of a reddit server. Your brower can now make the request to reddit’s server
Imagine that you are a supermarket making your first beer order from a microbrewery. You can’t just call the brewery floor and order the employees to deliver your beer! Instead, you call a salesperson or support agent that will help sure you understand how the logistics work- which distributor they use, how quickly they can deliver etc. The sales agent is like the DNS server because they will share the process for actually completing an order.
After you accept all that, you can make a request to the production team, which specializes in brewing beer.

So, in order:
- Browser like Chrome enters url reddit.com
- Request goes to DNS server, which responds with IP address of a reddit server
- Browser now makes request to reddit server
- Reddit server responds with home page
This is sometimes called “separation of concerns“- it allows each server to execute a specialized function so that each part can work most efficiently.
An Explanation of Ports
A microbrewery does not handle just one type of request! In any given week, it might be handling:
- Bills from its suppliers (eg bottling company, hops provider)
- Orders from customers (as discussed above)
- Job applications from new candidates
Each one of those types of requests must go to a specialized person in the brewery.
- Bills go to accounting department
- Orders go to operations team
- Job apps go to HR department

Just like a microbrewery, a server has pathways for different types of requests. These are called ports. Some common port examples include:
Port 25- SMTP (e-mail routing)
Port 80- HTTP (web requests as described above)
Port 143- IMAP- email management
These ports allow hosts on the internet to interact in a standardized way. If there was no common server configuration, the internet would not be able to perform like it does today. Instead, it would force custom configuration to interact with servers from different companies, which would make it harder for end users to interact in a seamless, smooth fashion like they do today
Where does the database fit in?
So far, we have covered the path of a single request to a web server. On the front-end, you would write the code in JavaScript, and the server would handle the request using a language like Python or PHP, or a framework like node.js.
But we have not yet covered the part where the database comes into play! The database is written in SQL or MongoDB, or a range of other languages used to build relational databases. But, it is not stored on the same server that we have been using so far!
Let’s return to our microbrewery. The raw materials used to make beer include
- Bottles
- bottle caps
- Hops
- Malt
- Water
Your brewery might store small quantities of these ingredients on site, but it probably also uses external warehouses. For example, you wouldn’t want to have thousands or tens of thousands of bottles sitting around the brewery. That’s excessive. These ingredients are kind of like the information stored in a database.
That external warehouse is kind of like a server that specifically runs a database, or a database server. We separate this functionality as well to make it as efficient as possible.
A database is just a digital structure that stores data. But a server provides all the operational protocols that allow that database to participate in a network.
So, let’s say that a customer makes a big order for 1000 cases of beer. The microbrewery will need to communicate with the warehouse to deliver some more bottles. That is another request-response cycle!

In this case, a server is acting as both a client AND a server. It is taking a request from an end-user, but also sending a request to another server afterwards. Its response depends on the response of the database server.

The end user does not see any of this, of course. From their perspective, they sent a request and received a response. They don’t see the server communication behind the scenes.
Real-Life Example of Databases + Servers
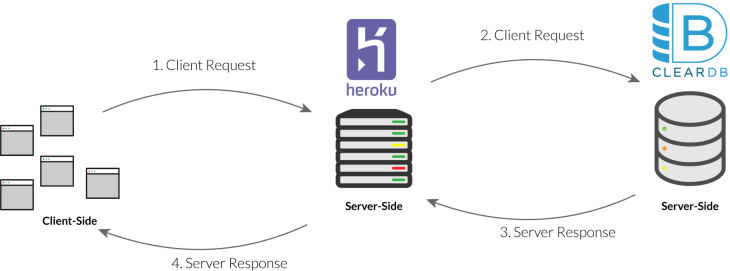
Heroku is a cloud service that allows web developers to easily deploy their apps with as little code and ongoing management as possible. It uses virtual containers, which allow you to rent a fraction of a full server to run your app. That’s a topic for another tutorial.
Anyways, Heroku allows you to push your latest commits live to your virtual container with a simple command: git push heroku master. Then, those changes will go live after you purchase a domain from a service like Namecheap, and connect it to your Heroku app.
But, if you want to use a database with your live app (you probably will), you will still need a separate hosting solution for that database! I recommend ClearDB, which has an app in Heroku’s marketplace. ClearDB has a generous free version that scales up as your database grows.
So, if you use this stack, here is what the process would look like when an end user makes a request that requires you to access the database.
Get The Latest Tutorials
Did you enjoy this explanation? Let me know in the comments, or sign up here to get the latest tutorials.

Love the detailed explanation.!!
This is awesome, thank you so much!!
Thanks for this! Found it really helpful.
Happy to help, Maliha 🙂
This is a great analogy Kevin – mega helpful!
Appreciate it Isobel!
This was useful.. I am new to Java and trying to get my head around…
Glad I could help!